


屏蔽AI蜘蛛和防止网站文章采集方法
时间:2024-10-16 12:49:57|栏目:Nginx|点击: 次

我从最经济实惠,简单粗暴开始说;不说废话,直接开整。
方法一:域名DNS托管到cloudflare,一键屏蔽AI爬虫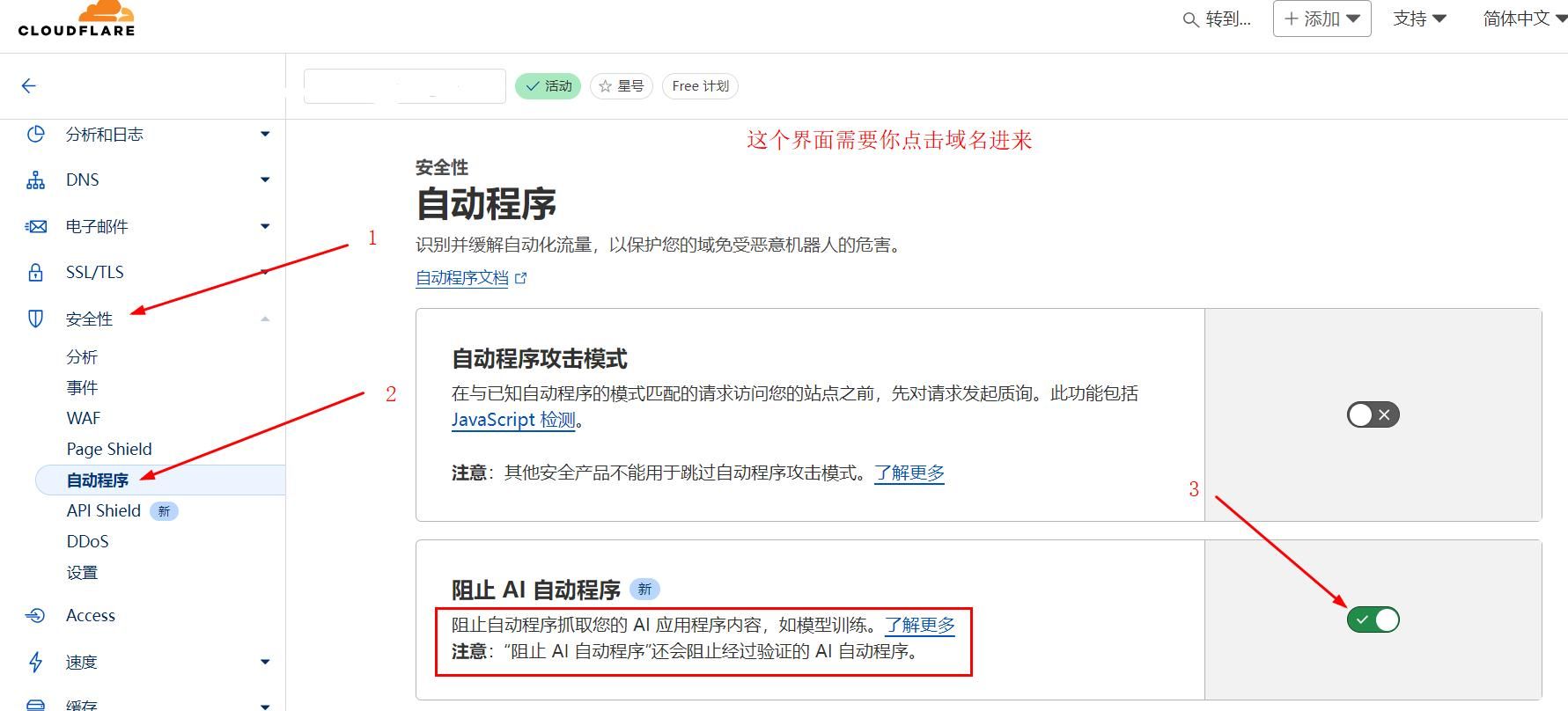
如果访问不了cloudflare,那就需要自己搞定梯子。
(国内域名几乎不影响访问速度,有些人会觉得使用国内DNS速度快,其实速度差不多)
方法二:宝塔防火墙设置屏蔽AI爬虫(我用的是破解版宝塔,免费版不知道能不能设置)
- Amazonbot
- ClaudeBot
- PetalBot
- gptbot
- Ahrefs
- Semrush
- Imagesift
- Teoma
- ia_archiver
- twiceler
- MSNBot
- Scrubby
- Robozilla
- Gigabot
- yahoo-mmcrawler
- yahoo-blogs/v3.9
- psbot
- Scrapy
- SemrushBot
- AhrefsBot
- Applebot
- AspiegelBot
- DotBot
- DataForSeoBot
- java
- MJ12bot
- python
- seo
- Censys
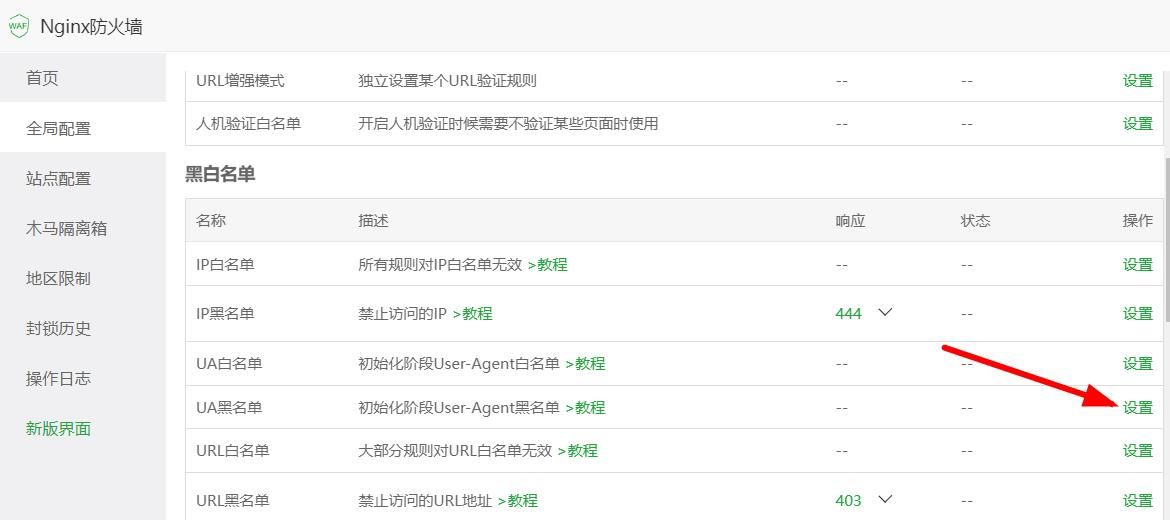
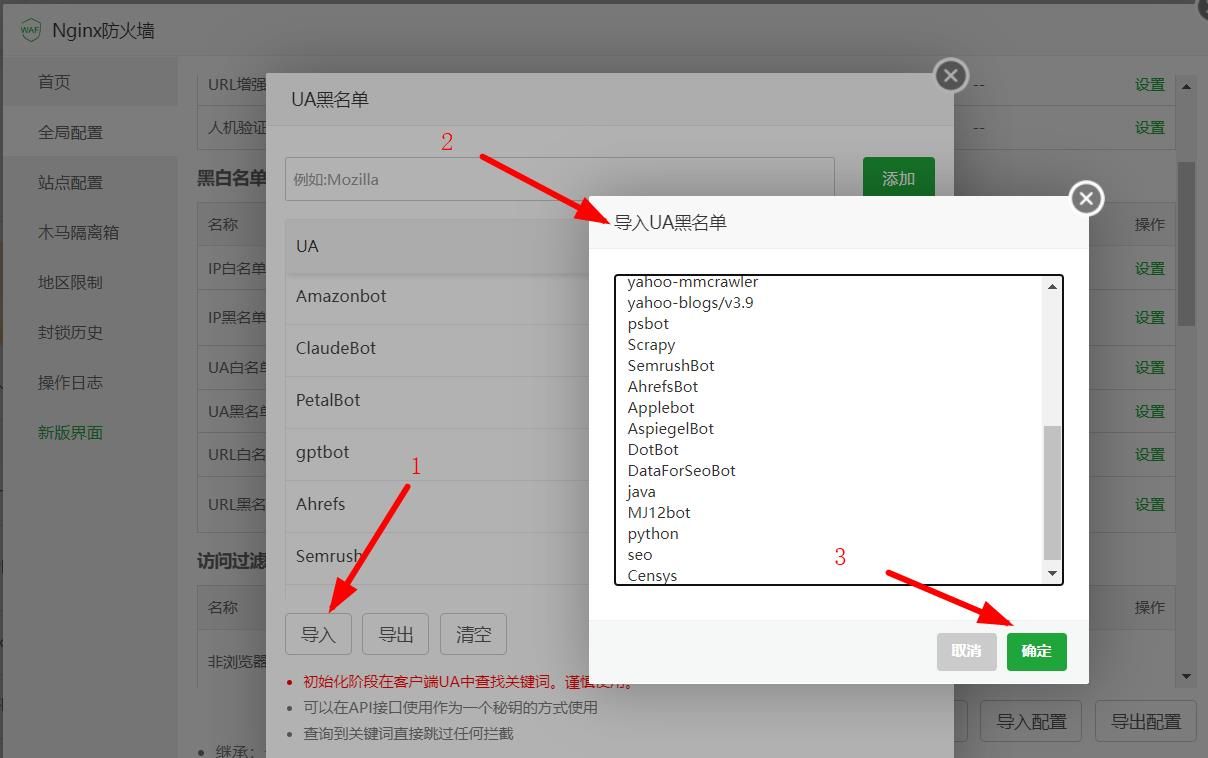
方法三:复制下面的代码,保存为robots.txt,上传到网站根目录
- User-agent: Ahrefs
- Disallow: /
- User-agent: Semrush
- Disallow: /
- User-agent: Imagesift
- Disallow: /
- User-agent: Amazonbot
- Disallow: /
- User-agent: gptbot
- Disallow: /
- User-agent: ClaudeBot
- Disallow: /
- User-agent: PetalBot
- Disallow: /
- User-agent: Baiduspider
- Disallow:
- User-agent: Sosospider
- Disallow:
- User-agent: sogou spider
- Disallow:
- User-agent: YodaoBot
- Disallow:
- User-agent: Googlebot
- Disallow:
- User-agent: Bingbot
- Disallow:
- User-agent: Slurp
- Disallow:
- User-agent: Teoma
- Disallow: /
- User-agent: ia_archiver
- Disallow: /
- User-agent: twiceler
- Disallow: /
- User-agent: MSNBot
- Disallow: /
- User-agent: Scrubby
- Disallow: /
- User-agent: Robozilla
- Disallow: /
- User-agent: Gigabot
- Disallow: /
- User-agent: googlebot-image
- Disallow:
- User-agent: googlebot-mobile
- Disallow:
- User-agent: yahoo-mmcrawler
- Disallow: /
- User-agent: yahoo-blogs/v3.9
- Disallow: /
- User-agent: psbot
- Disallow:
- User-agent: dotbot
- Disallow: /
方法四:防止网站被采集(宝塔配置文件保存以下代码)
- #禁止Scrapy等工具的抓取
- if ($http_user_agent ~* (Scrapy|Curl|HttpClient|crawl|curb|git|Wtrace)) {
- return 403;
- }
- #禁止指定UA及UA为空的访问
- if ($http_user_agent ~*
"CheckMarkNetwork|Synapse|Nimbostratus-Bot|Dark|scraper|LMAO|Hakai|Gemini|Wappalyzer|masscan|crawler4j|Mappy|Center|eright|aiohttp|MauiBot|Crawler|researchscan|Dispatch|AlphaBot|Census|ips-agent|NetcraftSurveyAgent|ToutiaoSpider|EasyHttp|Iframely|sysscan|fasthttp|muhstik|DeuSu|mstshash|HTTP_Request|ExtLinksBot|package|SafeDNSBot|CPython|SiteExplorer|SSH|MegaIndex|BUbiNG|CCBot|NetTrack|Digincore|aiHitBot|SurdotlyBot|null|SemrushBot|Test|Copied|ltx71|Nmap|DotBot|AdsBot|InetURL|Pcore-HTTP|PocketParser|Wotbox|newspaper|DnyzBot|redback|PiplBot|SMTBot|WinHTTP|Auto
Spider 1.0|GrabNet|TurnitinBot|Go-Ahead-Got-It|Download
Demon|Go!Zilla|GetWeb!|GetRight|libwww-perl|Cliqzbot|MailChimp|SMTBot|Dataprovider|XoviBot|linkdexbot|SeznamBot|Qwantify|spbot|evc-batch|zgrab|Go-http-client|FeedDemon|Jullo|Feedly|YandexBot|oBot|FlightDeckReports|Linguee
Bot|JikeSpider|Indy Library|Alexa
Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|UniversalFeedParser|ApacheBench|Microsoft
URL Control|Swiftbot|ZmEu|jaunty|Python-urllib|lightDeckReports
Bot|YYSpider|DigExt|HttpClient|MJ12bot|EasouSpider|LinkpadBot|Ezooms|^$"
) {
- return 403;
- }
- #禁止非GET|HEAD|POST方式的抓取
- if ($request_method !~ ^(GET|HEAD|POST)$) {
- return 403;
- }
添加完毕后保存,重启nginx即可,这样这些蜘蛛或工具扫描网站的时候就会提示403禁止访问。
注意:如果你网站使用火车头采集发布,使用以上代码会返回403错误,发布不了的。如果想使用火车头采集发布,请使用下面的代码:
- #禁止Scrapy等工具的抓取
- if ($http_user_agent ~* (Scrapy|Curl|HttpClient|crawl|curb|git|Wtrace)) {
- return 403;
- }
- #禁止指定UA及UA为空的访问
- if ($http_user_agent ~*
"CheckMarkNetwork|Synapse|Nimbostratus-Bot|Dark|scraper|LMAO|Hakai|Gemini|Wappalyzer|masscan|crawler4j|Mappy|Center|eright|aiohttp|MauiBot|Crawler|researchscan|Dispatch|AlphaBot|Census|ips-agent|NetcraftSurveyAgent|ToutiaoSpider|EasyHttp|Iframely|sysscan|fasthttp|muhstik|DeuSu|mstshash|HTTP_Request|ExtLinksBot|package|SafeDNSBot|CPython|SiteExplorer|SSH|MegaIndex|BUbiNG|CCBot|NetTrack|Digincore|aiHitBot|SurdotlyBot|null|SemrushBot|Test|Copied|ltx71|Nmap|DotBot|AdsBot|InetURL|Pcore-HTTP|PocketParser|Wotbox|newspaper|DnyzBot|redback|PiplBot|SMTBot|WinHTTP|Auto
Spider 1.0|GrabNet|TurnitinBot|Go-Ahead-Got-It|Download
Demon|Go!Zilla|GetWeb!|GetRight|libwww-perl|Cliqzbot|MailChimp|SMTBot|Dataprovider|XoviBot|linkdexbot|SeznamBot|Qwantify|spbot|evc-batch|zgrab|Go-http-client|FeedDemon|Jullo|Feedly|YandexBot|oBot|FlightDeckReports|Linguee
Bot|JikeSpider|Indy Library|Alexa
Toolbar|AskTbFXTV|AhrefsBot|CrawlDaddy|CoolpadWebkit|Java|UniversalFeedParser|ApacheBench|Microsoft
URL Control|Swiftbot|ZmEu|jaunty|Python-urllib|lightDeckReports
Bot|YYSpider|DigExt|HttpClient|MJ12bot|EasouSpider|LinkpadBot|Ezooms ) {
- return 403;
- }
- #禁止非GET|HEAD|POST方式的抓取
- if ($request_method !~ ^(GET|HEAD|POST)$) {
- return 403;
- }
设置完了可以用模拟爬去来看看有没有误伤了好蜘蛛,说明:以上屏蔽的蜘蛛名不包括以下常见的6大蜘蛛名:百度蜘蛛:Baiduspider谷歌蜘蛛:Googlebot必应蜘蛛:bingbot搜狗蜘蛛:Sogou web spider360蜘蛛:360Spider神马蜘蛛:YisouSpider爬虫常见的User-Agent如下:
- FeedDemon 内容采集
- BOT/0.1 (BOT for JCE) sql注入
- CrawlDaddy sql注入
- Java 内容采集
- Jullo 内容采集
- Feedly 内容采集
- UniversalFeedParser 内容采集
- ApacheBench cc攻击器
- Swiftbot 无用爬虫
- YandexBot 无用爬虫
- AhrefsBot 无用爬虫
- jikeSpider 无用爬虫
- MJ12bot 无用爬虫
- ZmEu phpmyadmin 漏洞扫描
- WinHttp 采集cc攻击
- EasouSpider 无用爬虫
- HttpClient tcp攻击
- Microsoft URL Control 扫描
- YYSpider 无用爬虫
- jaunty wordpress爆破扫描器
- oBot 无用爬虫
- Python-urllib 内容采集
- Indy Library 扫描
- FlightDeckReports Bot 无用爬虫
- Linguee Bot 无用爬虫
复制代码
转自:
您可能感兴趣的文章
- 10-16屏蔽AI蜘蛛和防止网站文章采集方法
- 11-22Nginx实现跨域使用字体文件的配置详解

